Neural Network는 여러개의 Linear Classifier을 겹쳐 놓은 것이다.
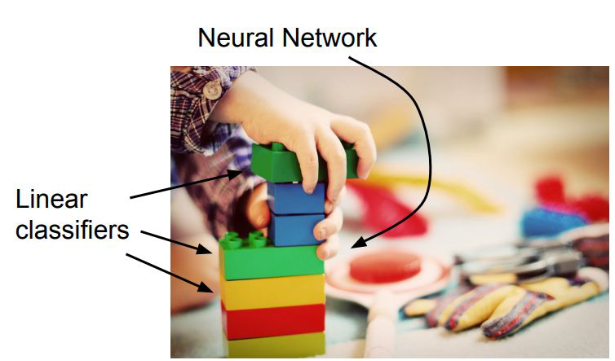
Linear Classifier를 다르게 말해본다면 A simple parametric model이라고도 할 수 있다.
f(x, W) = Wx + b

f는 x와 W를 컴포넌트로 가지고 있는 Classifier라고 보면 된다.
x는 vector format, W는 weight format이다.
b는 bias라고 해서 offset을 뜻하는데 생략 가능하다.
bias 같은 경우 데이터셋이 unbalance한 경우, 기존 데이터셋과 무관하게 특정 클래스에 더하여 우선권을 부여할 수 있다.
Linear Classifier의 한계

해당 이미지같은 녀석들은 분류를 하지 못한다.
예를 들어 Image Classification에서 사람수가 홀수명 있는지, 짝수명 있는지 판별하는 문제에서 동작하지 못한다.
빨강색 클래스와 파란색 클래스를 선을 그어서 나눌 수 있는 방법이 아예 없다.
Loss Function
Linear Classification에서 W가 predict를 잘 하는지, 못 하는지가 필요하다.
이것을 어떻게 정량화 할 수 있는지, 그 matrix이 필요한 것인데 이것이 Loss function이다.
즉 W가 얼마나 나쁘고 좋은지를 알려주는 척도이다.
쉽게 요약해서 모델에서 예측한 값을 실제 데이터값과 비교해서, 그 차이의 값을 측정하는 함수이다.
그리고 좋은 W를 찾아가는 과정, Loss function을 minimize 하는 과정을 Optimization이라 한다.

Loss를 위의 식처럼 define 할 수 있다.
각 샘플마다 얼마나 나쁜지를 matrix을 측정하고 다 더한 값을 N개로 나눠, normalization하면 된다.
Softmax Function
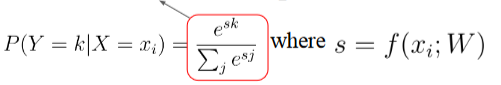
간단하게 활성화 함수라고도 불리기도 한다. 다른 활성화 함수로는 ReLu, Sigmoid가 있다.
Softmax Funcition은 classifier된 값들을 0과 1사이로 변환하여 출력하며 Positive값과 Negative값의 합이 항상 1이 되게끔 한다. ('다중 분류 모델의 마지막 활성화 함수' 라고 보면 된다.)
Optimization
Loss Function의 값을 최소화 하는 파라미터를 구하는 과정이다.
위에서 말했듯이 Loss Function이 예측값과 실제값의 차이를 측정한 값을 가지고 그 값을 최소화 하기 위한 함수이다.
Loss Function(예측값과 실제값 사이를 측정하기만 함)
Optimization(측정한 Loss Function값을 가지고 최적화, 최소화를 함)
Optimization에서 가장 대표적인게 Gradient Desenct Algorithm인데, 이 알고리즘은 다음과 같이 작동된다.

Gradient Descent는 중요한 녀석이므로,, 다음 게시물로 올려야겠다.
'AI' 카테고리의 다른 글
| [NLP] 시작 (5) | 2025.04.16 |
|---|---|
| Transformer (0) | 2024.12.16 |
| Seq2Seq Text Generation (0) | 2024.12.13 |
| Language Model (0) | 2024.11.29 |
| Image Classification, Text Classification (0) | 2024.09.23 |



